India is home to one of the world’s most linguistically diverse populations—yet, until now, artificial intelligence (AI) has largely ignored this fact. Today, we’re proud to introduce Param-1, a groundbreaking 2.9 billion parameter bilingual language model designed with India at its core.
The Problem: AI’s Language Barrier
Modern large language models like GPT-4, LLaMA, and others are impressive—but they’re primarily trained on English. Consider this: Meta’s LLaMA dedicates just 0.01% of its training data to Indic languages, despite India accounting for nearly 18% of the global population.
This creates major accessibility issues for the 1.4+ billion Indians who speak 20+ official languages and 100+ dialects:
- Poor comprehension of Indian languages and contexts
- Culturally irrelevant or biased outputs
- Ineffective tokenization of Indian scripts
- Lack of support for regional and government use cases
Introducing Param-1: AI Built for India
Param-1 is not a retrofitted Western model—it’s been built from the ground up for India’s multilingual reality. A bilingual Hindi-English model, Param-1 understands and responds naturally in both languages, providing equitable access to high-quality AI tools.
Core Design Principles of Param-1
- Equitable Language Representation
Param-1 allocates 25% of its training data to Hindi, a significant leap compared to the negligible representation in traditional models. Out of 7.5 trillion tokens, 2.77 trillion are dedicated to Hindi content.
- Tokenization Fairness
Param-1 uses a custom SentencePiece tokenizer with a 128K vocabulary, optimized for Indian scripts and morphology. This dramatically improves processing for Hindi and related languages compared to Western-trained tokenizers.
- Culturally Aligned Evaluation
The model is evaluated on India-specific benchmarks, including code-mixed reasoning and socio-linguistic robustness, not just English-centric tasks.
Technical Architecture: Built for Performance
Param-1 follows a decoder-only casual language model model architecture similar to GPT and LLaMA, but with optimizations for multilingual and Indian culture specific performance:
Architecture attributes | Values |
model_type | causal-language-model |
hidden_size | 2048 |
intermediate_size | 7168 |
max_position_embeddings | 2048 |
num_of_attention_heads | 16 |
rope_theta | 10000 |
num_of_decoder_blocks | 32 |
seq_length | 2048 |
num_of_key_value_heads | 8 |
activation_function | Swiglu |
attention | Grouped-query attention |
precision | bf16-mixed |
Three-Phase Pre-training Strategy
Phase 1: Bootstrap Training
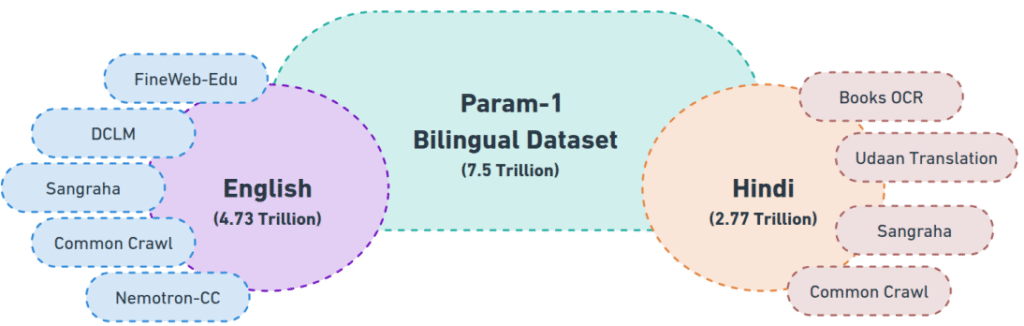
- 5T tokens (4.73T English + 2.77T Hindi)
- Trained on 64 nodes with 8× NVIDIA H100 GPUs each
- Datasets: FineWeb-Edu, DCLM, Nemotron-CC, Sangraha, Books OCR, Udaan
- Data curation techniques: FastText detection, toxic content removal, Unicode normalization, deduplication, PII removal
Phase 2: Factual Consistency
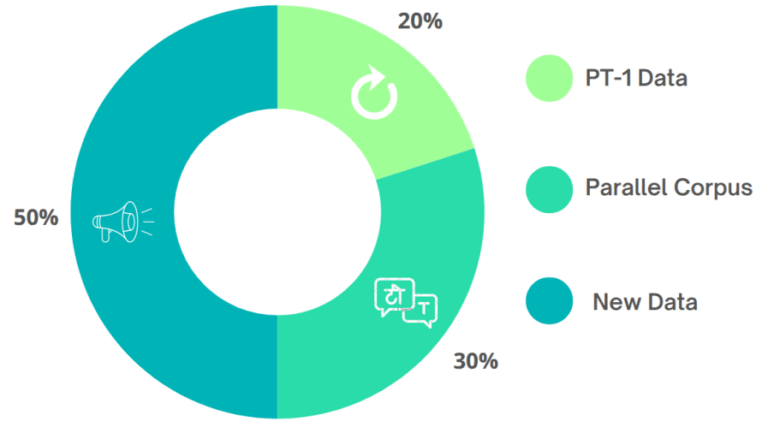
- Focused on improving knowledge retention and factual correctness
- Uses enhanced monolingual and bilingual corpora with Indian context emphasis
Phase 3: Long-Context Adaptation
- 500B tokens (250B English + 250B Hindi)
- Document lengths range from 2K to 16K+ tokens
- Trains long-range dependency and memory performance
Custom Tokenizer Advantage
The BharatGen tokenizer outperforms popular alternatives in Indian language efficiency:
Language | BharatGen-128K | LLaMA | Qwen |
Hindi | 1.43 | 2.65 | 4.66 |
Lower scores mean better token efficiency.
Benchmark Evaluation & Baseline Comparisons
To thoroughly evaluate Param-1’s capabilities, we benchmarked its pretraining checkpoint against a range of open-weight language models of similar scale (2–3B parameters). These evaluations span general reasoning, knowledge recall, and most importantly, Indian language and cultural understanding.
Param-1 demonstrates competitive performance across standard benchmarks while excelling in Indian language tasks. The provided benchmarks results are of Pre-Trained (PT) checkpoints.
Task | Param1 2.9B | Sarvam1 2B | Qwen2.5 3B | Gemma2 2B | Llama3.2 3B | Granite3.1 2B |
Hella Swag Hi | 45.7* | 43.8* | 32.9 | 39.1* | 40.6* | 31 |
MMLU (Hi) | 36.1* | 41.4* | 38.32 | 35.8* | 37.5* | 29 |
SANSKRITI | 60.15 | 52.61 | 69.72 | 69.76 | 55.47 | 60.95 |
MILU (Hi) | 30.17 | 28.48 | 33.6 | 29.17 | 29.36 | 26.06 |
MILU (En) | 36.3 | 32.12 | 49.84 | 44.65 | 37.63 | 36.08 |
Table1 – Performance on India centric Benchmarks
Task | Param1 2.9B | Sarvam1 2B | Qwen2.5 3B | Gemma2 2B | Llama3.2 3B | Granite3.1 2B |
ARC challenge | 52.9* | 54.4* | 47.4 | 52.9* | 50.8* | 47.2 |
ARC Easy | 74.6 | 80.3 | 73.2 | 80.3 | 71.7 | 76.8 |
Hella Swag | 73.4* | 67.6* | 73.6 | 74.6* | 76.3* | 75.5 |
MMLU En | 46* | 47.7* | 64.9 | 52.6* | 54.8* | 47.8 |
PIQA | 79.3 | 76.4 | 78.84 | 78.3 | 77.31 | 79.4 |
TriviaQA | 38.5 | 32.2 | 42.27 | 32.9 | 50.83 | 26.2 |
LogicQA | 28.3 | 30.1 | 33.49 | 30.4 | 30.41 | 29.5 |
Winogrande | 61.6 | 61.2 | 68.27 | 68.5 | 68.9 | 71.7 |
TruthfulQA- gen- blue | 38.2 | 36.3 | 36.96 | 29.7 | 21.8 | 34 |
lambda_openai_acc | 61.9 | 61 | 66.89 | 70 | 70.1 | 71.4 |
lambda_standard_acc | 57.6 | 56.3 | 59.09 | 64.1 | 63.8 | 65.7 |
Table2 – Performance on various general language understanding benchmarks
* – Few shot results
Param1 2.9B delivers robust and competitive performance across a wide range of general language understanding benchmarks, consistently matching or exceeding other leading models in several key tasks.
Baseline Models for Comparison
We compare Param-1 with several leading models in the 2–3B parameter range:
- Sarvam-1 (2B): A Hindi-focused language model trained specifically for Indian use cases, offering a direct comparison for Param-1’s bilingual capabilities.
- Qwen 2.5 (3B): A high-performance model with strong reasoning abilities, thanks to training on expert-curated datasets for coding and mathematics. It’s a valuable baseline for multilingual and logic-based tasks.
- Gemma-2 (2B): DeepMind’s smallest Gemma variant, emphasizing efficiency, long-context comprehension, and numeracy with English and code-heavy datasets.
- Granite 3.1 (2B Dense): IBM’s multilingual model trained on 12 trillion tokens, designed for reasoning, instruction following, and enterprise-grade use.
- LLaMA 3.2 (3B): A distilled variant of Meta’s LLaMA 3.1 70B model, optimized for general-purpose tasks. Despite strong performance, it includes minimal Indic representation (0.01%), making it a benchmark for contrast.
Benchmark Suite
Knowledge & Reasoning: ARC (Challenge & Easy), MMLU & MMLU-Hi, TriviaQA, LogiQA, TruthfulQA, LAMBADA & Lambda-OpenAI.
Commonsense & Physical Reasoning: HellaSwag (EN & HI), Winogrande, PIQA
Indian Language & Cultural Proficiency: MILU (Multilingual India-Level Understanding), SANSKRITI (Focuses on Indian culture, with over 21K multiple-choice questions across history, festivals, cuisine, and more)
Alignment and Safety: Building Responsible AI
Prometheus Evaluation (Instruction Tuning)
Assessed with 1,000 prompts across categories:
- Helpfulness
- Factual correctness
- Reasoning
- Safety
Param-1 shows strong preference in bilingual settings, ensuring reliable responses across English and Hindi.
LLM360 Safety Suite
Tested against:
- Identity-based toxicity
- Threatening content
- Profanity and slurs
Param-1 maintains low toxicity and demonstrates safe, culturally aware behavior even in adversarial prompts.
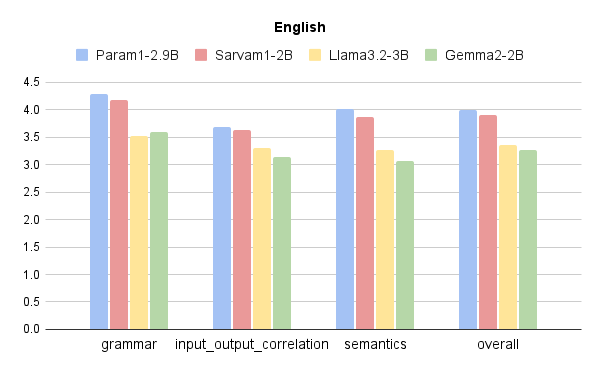
This evaluation provides a quantitative preference score without human annotation, offering a scalable and objective measure of Param-1’s alignment. Notably, Param-1 demonstrated high alignment fidelity in bilingual queries, showcasing its ability to respond accurately and helpfully across English and Hindi prompts.
Toxicity Evaluation
We evaluated safety and toxicity mitigation using the LLM360 Safety Evaluation Suite, a robust benchmark designed to test LLMs on potentially harmful content generation.
Using the toxicity sub-suite, Param-1 was prompted with a curated set of adversarial and stereotype-sensitive queries in both English and Hindi. Toxicity was measured using classification tools like Detoxify and Perspective API, with breakdowns by content category:
- Identity-based toxicity
- Profanity and slurs
- Threatening or violent language
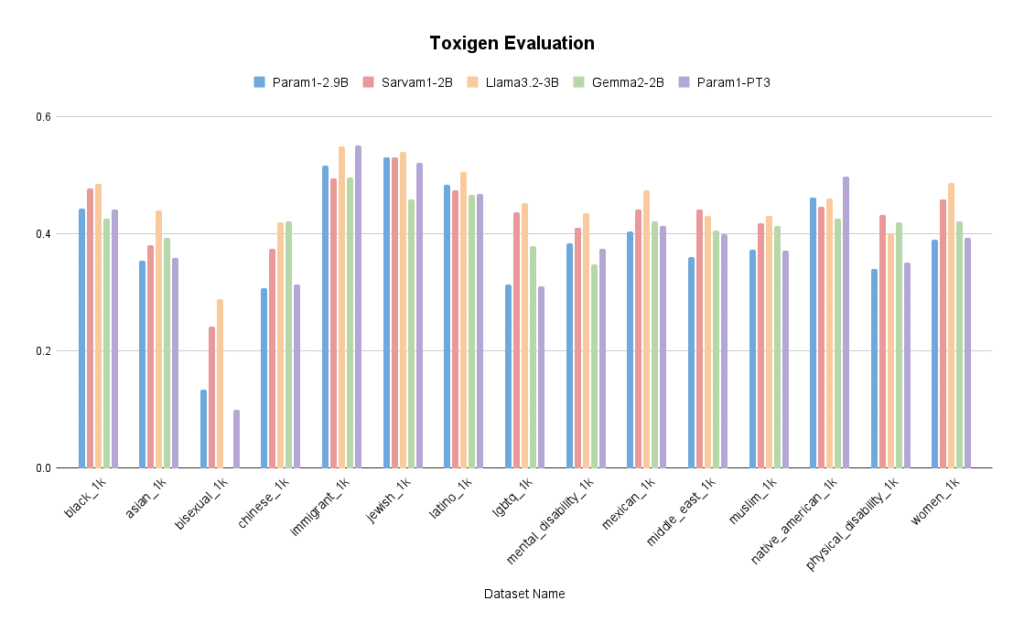
Param-1 maintains low toxicity scores across both monolingual and bilingual prompts.
Its instruction-tuned checkpoint is more effective in rejecting or redirecting unsafe queries, ensuring higher trust in sensitive deployments.
Real-World Use Cases
Param-1 is ready to power India’s most critical sectors:
- Governance – Multilingual digital services
- Education – AI tutors for diverse learners
- Healthcare – Region-specific medical assistants
- Legal – Understanding local laws and regulations
- Agriculture – Farmer outreach in regional languages
Instruction Fine-Tuning for Real Impact
Param-1 is ready to power India’s most critical sectors:
- 400K high-quality instruction-response pairs
- Bilingual corpus from Indian domains
- Domain-specific content (governance, education, culture)
- Rigorous safety and relevance checks
Infrastructure and Scale
Trained using Yotta’s high-performance SLURM-managed cluster:
· 8× NVIDIA H100 GPUs per node
· High-speed InfiniBand interconnect
· NeMo Framework for efficient distributed training
Why Param-1 Matters: A Paradigm Shift
Param-1 is more than a model—it’s a blueprint for equitable AI. It proves that linguistic inclusivity and technical excellence are not mutually exclusive.
By embedding diversity into its foundation—not as an afterthought—Param-1 sets the standard for AI made in and for the Global South.
Get Started with Param-1
The Param1 Model is available on AIkosh and HuggingFace for public use and further research.
Join us in shaping the future of inclusive AI.
About BharatGen
Developed by the BharatGen team, Param-1 is a pioneering step toward building democratic, multilingual AI that reflects and serves India’s unique linguistic landscape.