Every day, billions of documents change hands. A hospital sends a discharge summary. A bank issues a loan agreement. A logistics company generates a customs form. An analyst reviews a quarterly earnings filing. These aren’t simple text files. They’re visual objects pages designed for human eyes, with numbers nested inside tables, text wrapping around images, fine print curling along a poster edge, labels arching over a chart. Some are born digitally as clean PDFs. Others are photographs of paper tilted, faded, stamped, signed. The same information can live in a table cell, a chart bar, a watermarked footer, or curved text on a banner. No two documents look the same.
Humans navigate this effortlessly. We skim, scan, zoom in on a number, flip back to cross-reference a clause. We instinctively know the revenue figure is in the top-right cell of that table, not in the footnote three lines below it.

But there’s a catch that nobody talks about enough. These models tell you what the answer is. They don’t show you where it came from. For casual use, that’s fine. But a lawyer verifying a contract clause, a doctor reviewing lab values, a compliance officer checking a regulatory filing, none of them can afford to just trust the AI’s word. They need to see the evidence. The exact sentence. The specific row. The precise cell the model is pointing at.
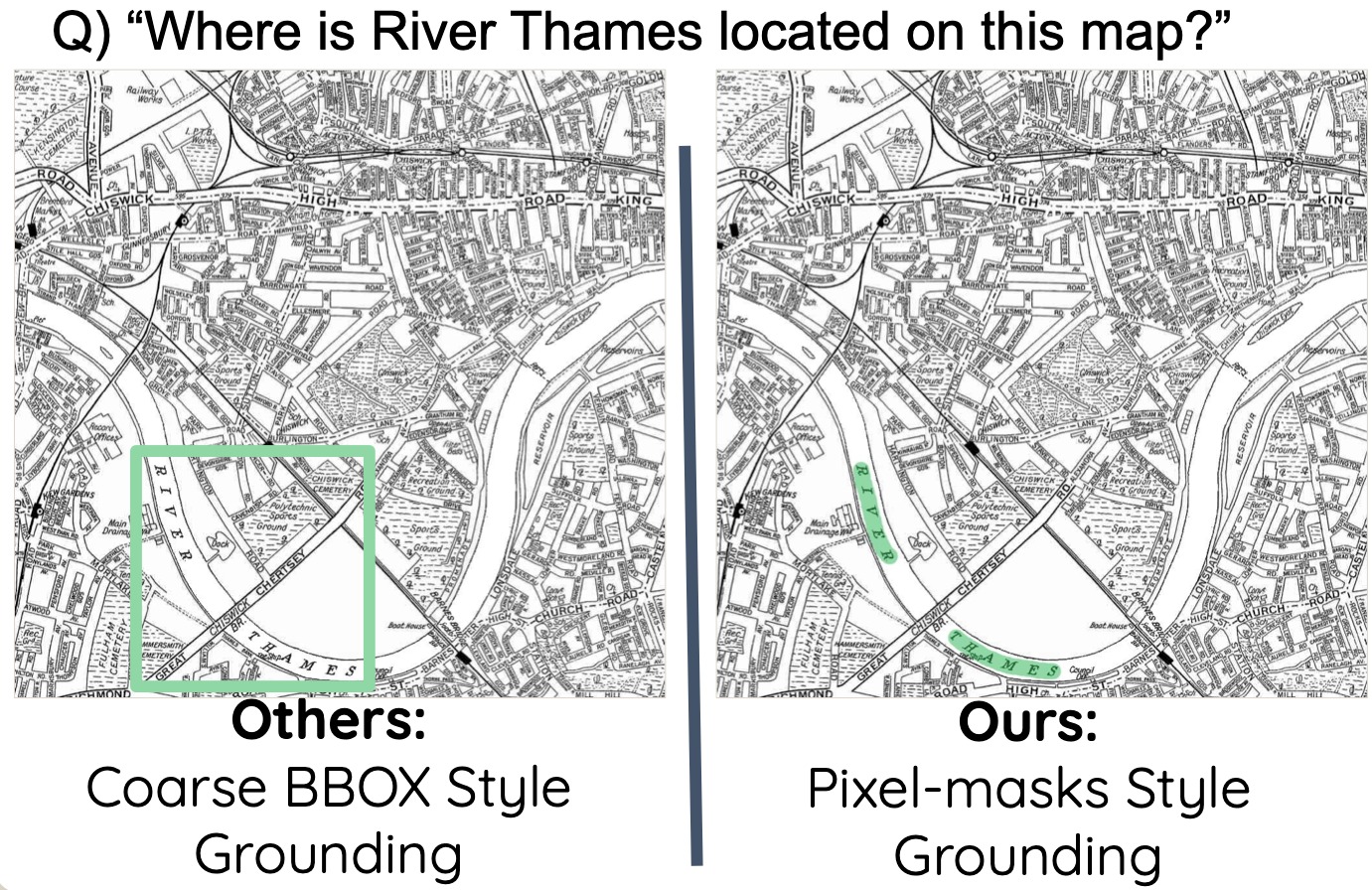
And showing that evidence is genuinely hard. The word “Total” might appear fourteen times on a single invoice, which one is the answer? Some documents have text that curves around a logo or runs at an angle; a rectangular box drawn around it captures mostly background noise.
M3Grounder, short for Mask-Based Multi-Span and Multi-Granular Grounding for Document QA, was built to close exactly this gap. Not just answering the question; but highlighting, on the actual page, the exact evidence behind it. Like a careful human reader with a highlighter, working in real time.
This work comes out of BharatGen’s vision team, in collaboration with IIIT Hyderabad, a founding member of the BharatGen consortium. BharatGen is India’s first sovereign AI initiative, built on a core belief that AI deployed in high-stakes settings must be trustworthy, not just accurate. M3Grounder is part of that effort. Think of it as a recipe for building grounding capability into document AI systems, and one part of a growing suite of models under the Patram ecosystem, India’s first Vision-Language Document Foundation Model built for Indic document intelligence.
What makes it distinct is where the grounding actually happens. Most existing systems that attempt to localize answers operate on the text modality, matching the predicted answer string back to OCR output and drawing a box around it. M3Grounder skips that entirely. It grounds end-to-end, directly on the image, producing pixel-level segmentation masks without ever relying on OCR as an intermediate step. That is not just a technical difference. It is what makes the system reliable on documents where OCR pipelines routinely break down.
“The future of document AI isn’t just answering questions. It’s answering and showing its work.”
The Problem With Document AI Today
Approach 1: “Just output coordinates.”
Some models are trained to print the bounding box of the answer — literally generating numbers like [x1, y1, x2, y2] as part of their text output. This seems reasonable until you realise how brittle it is. The model is juggling two completely different jobs at once inside a single output stream: understanding language and producing precise pixel coordinates. A small error in one corrupts the other. And because these coordinates are generated token-by-token like regular words, the model has no native spatial awareness, it’s guessing geometry through grammar.
Approach 2: “Match the answer text back to OCR.”
Other systems run OCR first, extract all the text from the document, find where the answer string appears in the OCR output, and draw a box around it. This works for simple cases but fails the moment reality gets complicated: What if the word “Total” appears six times on a page? What if the answer comes from a curved banner or a chart axis where OCR alignment is already unreliable? The pipeline breaks down and the highlighted region becomes guesswork. Both approaches share a deeper problem: they try to do language and spatial reasoning in the same place, through the same mechanism. The result is that one always suffers.
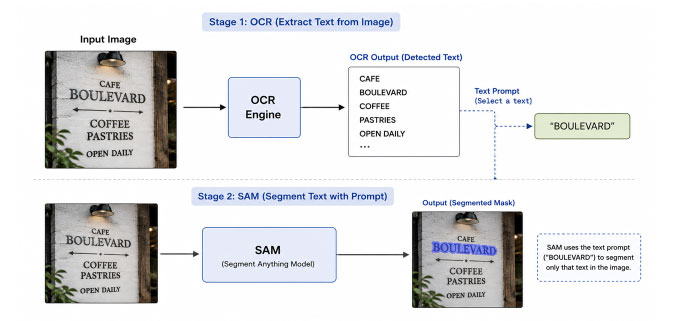
The naive approach: run OCR to find text, then separately prompt a segmentation model. Two stages, two failure points, no end-to-end learning
The Solution: Stay in the Latent Space (A smart highlighter)
M3Grounder’s key insight is that you should never have to leave the model’s internal representation to do grounding. Instead of going outside the latent space to extract text and then prompt a separate model, the VLM can natively learn latent representations that act as tool calls to a segmentation model. Think of it like function calling in LLMs, but for vision: the VLM doesn’t output coordinates or text strings; it produces a learned internal signal that directly invokes SAM to generate masks.
When a language model processes a document and generates an answer like “BOULEVARD”, it has already built up a rich internal understanding of that word, what it means, where it appeared, what visual context surrounds it. That understanding lives as a vector of numbers inside the model: a hidden state. Most approaches throw this away — either forcing the model to convert it back to raw coordinates (brittle), or exiting the model entirely to run OCR and match text strings (slow and ambiguous). M3Grounder does something different: it uses the hidden state directly as a visual prompt.
The system is built around two modules working in parallel:
- A Vision-Language Model (VLM) reads the document and question, then generates the answer word by word. We add a special [GROUND] token to the model's vocabulary and train the VLM to learn two things simultaneously: what to answer, and when to ground within that answer. Whenever the model determines that a piece of the answer needs evidence, it predicts a [GROUND] token right there; mid-answer, as a trigger. That trigger's hidden state is a compact encoding of everything the model understood about that span: its meaning, context, and relationship to the document.
- A Segment Anything Model (SAM) runs independently, extracting dense visual features from the same document image building a rich pixel-level map of the page.
The handshake and the key insight is that the [GROUND] token’s hidden state is projected by a small MLP into the exact format SAM expects as a prompt. From SAM’s perspective, it’s receiving a normal input prompt and doing what it was always designed to do: segment. But that prompt wasn’t typed by a human or extracted by OCR. It was natively learned by the VLM during training a latent representation that encodes what to ground and where, produced entirely within the model’s own internal space. This is a tool calling for vision: the VLM invokes SAM with a learned signal, never leaving the latent space, and SAM produces a precise pixel mask. No OCR, no coordinate generation, no staged pipeline.
The VLM never has to “speak coordinates.” SAM never has to “understand language.” Each does what it’s natively good at. The hidden state is the bridge: a natively learned latent representation that serves as a tool call from one model to the other.
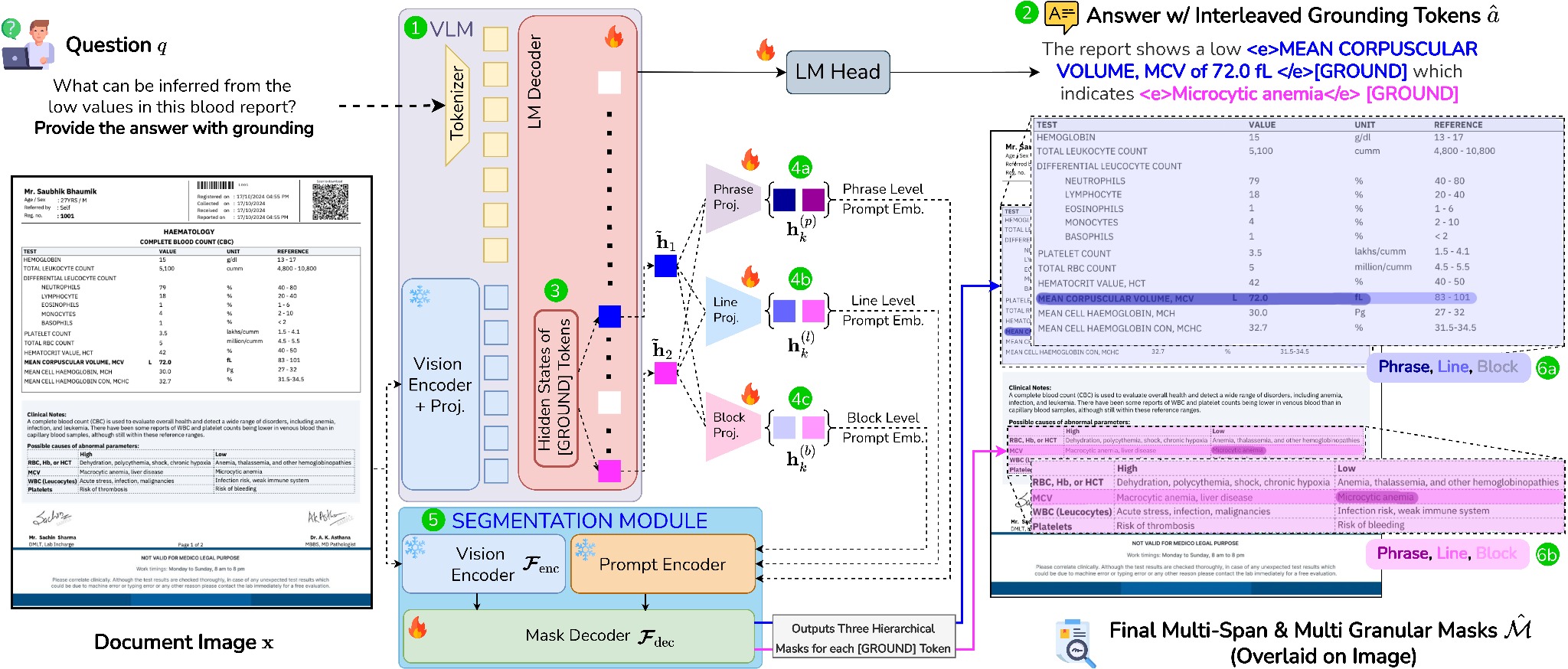
Overview of M3Grounder. Given a document image and question, a VLM (1) encodes visual features and autoregressively generates an answer sequence (2) interleaved with [GROUND] tokens. Hidden states of the [GROUND] tokens (3) from the VLM decoder are passed through granularity-specific MLP projection heads, producing phrase, line, and block level prompt embeddings (4). In parallel, the promptable segmentation module (5) extracts dense image embeddings reused across all spans and granularities. The prompt embeddings (4) are decoded by the mask decoder to generate hierarchical grounding masks (6), mapping each answer span to its corresponding grounding masks across multiple granularities.
This design has a meaningful side effect: because the grounding signal comes from the model’s own latent understanding rather than string matching, M3Grounder can ground text it has never seen OCR’d curved text on posters, rotated labels in diagrams, stamps. The geometry is handled by SAM’s pixel-level machinery, not by fragile text coordinates. The result: a single forward pass produces both the answer and its evidence, end-to-end.
Three levels of detail you choose how zoomed-in you need:
Phrase Level
Line Level
Block Level
Each level strictly contains the one above it: phrase ⊂ line ⊂ block
One Pass. No Staged Pipeline.
A staged pipeline — where you first run OCR, then separately prompt a segmentation model — has to solve a hard alignment problem every time: which of the OCR-detected tokens corresponds to the model’s intended answer? In documents with repeated phrases, dense tables, or ambiguous layouts, that alignment frequently fails.
M3Grounder sidesteps this entirely. The [GROUND] token is generated immediately after the answer span in the same autoregressive pass that produced the answer. Its hidden state already knows what the answer is and where in the document it came from because it was computed while reading that document. There is no external lookup, no string matching, no second model that needs to be told what to find. The only cost of adding grounding to the system is 63 milliseconds of extra latency per query, the time for SAM to decode the masks. The VLM’s answer quality is completely unchanged.
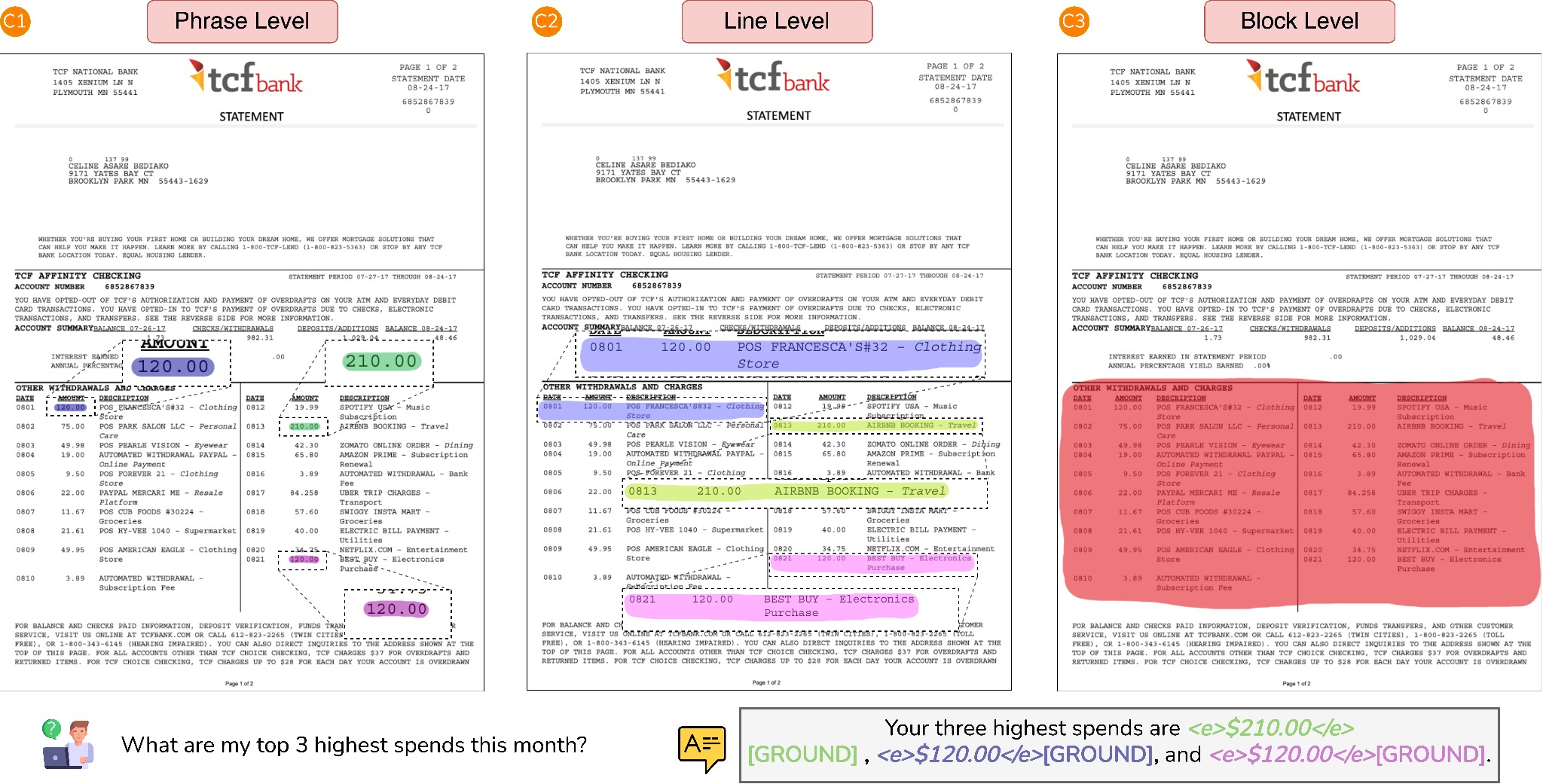
Example of multi-granular grounding in document QA. The model grounds the same answer at three levels of granularity-phrase, line, and block, showing its ability to localize evidence at different contextual scopes.
A precise date? Phrase level. The surrounding paragraph? Block level. The choice gives users and downstream applications the right level of evidence for the task at hand.
Why Does This Matter?
Finance
Legal
Healthcare
Enterprise
The Numbers
To build and test M3Grounder, the team created an entirely new dataset GroundingDocQA, the largest of its kind for pixel-level document grounding.
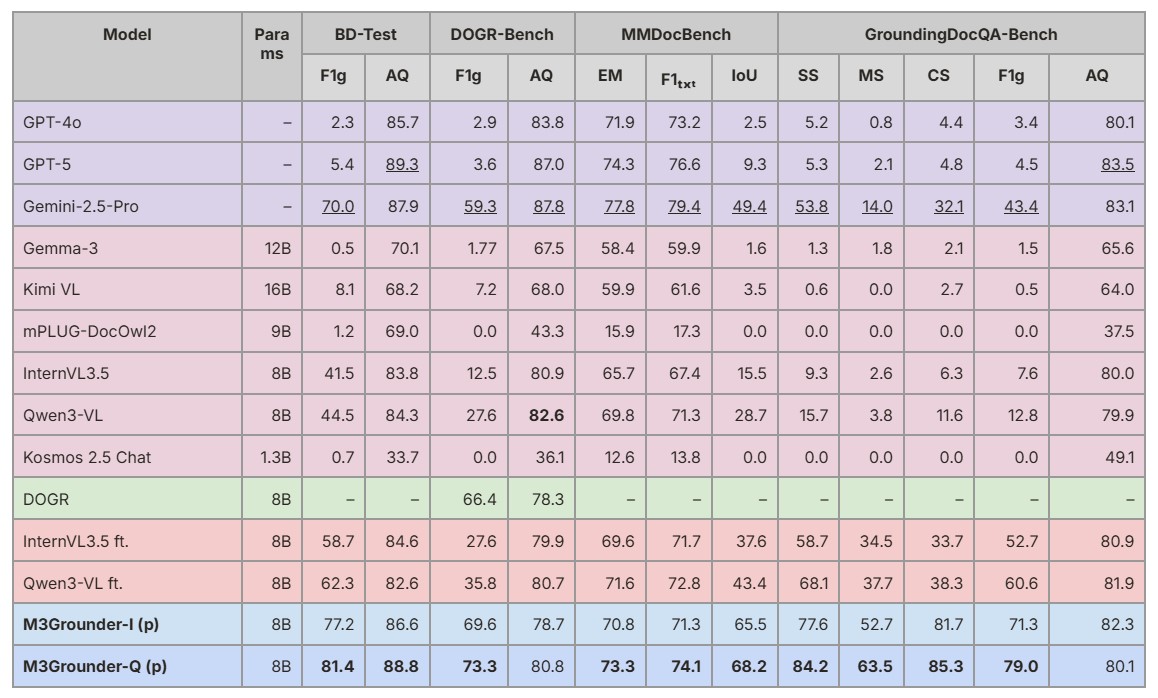
How Does It Compare?
M3Grounder was tested against leading commercial and open-source AI systems. Here’s a simplified look at performance on the hardest metrics curved and multi-span text grounding:
| Model | Multi-span grounding | Curved text grounding | Open source |
|---|---|---|---|
| GPT-4o (OpenAI) | ✗ 5.2% | ✗ 0.8% | ✗Closed |
| Gemini-2.5 Pro (Google) | 53.8% | 14.0% | ✗Closed |
| Qwen3-VL fine-tuned | 68.1% | 37.7% | ✓Open |
| M3Grounder (Ours) ★ | ✓ 84.2% | ✓ 63.5% | ✓Open |
The gains are especially large for curved text, the hardest case, where rectangular boxes simply can’t work. This is where segmentation-based grounding shines.
What's Next
M3Grounder was presented at CVPR 2026 in Nashville, one of the most competitive venues in computer vision, where fewer than 25% of submitted papers are accepted. For BharatGen’s Vision team, it’s a validation that research built around India’s document challenges belongs at the frontier of the field, not at the periphery of it.
Grounding is one of the capabilities we’re investing in most deeply as part of the Patram ecosystem. There’s more coming from this direction.
But the reason any of this matters comes down to something simple. Across India, consequential documents like land records, medical reports, court filings, and government certificates are still handled as physical objects, photographed and passed around as images. The people who depend on these documents deserve AI that doesn’t just read them but can show its work, pointing at the exact line, the precise field, the specific stamp that supports what it found. That’s what pixel-precise grounding is for. Not a research benchmark. A practical guarantee.
This blog describes research conducted by BharatGen‘s Vision team in collaboration with IIIT Hyderabad, a founding consortium member. The paper was accepted and presented at CVPR 2026.

Research by: Venkat Kesav Venna, Sai Madhusudan Gunda, Jyothi Swaroopa Jinka, Hrithik Sagar Rachakonda, Anirudh Srinivasan, Ravi Kiran Sarvadevabhatla
Project page: m3grounder.github.io