The Challenge: AI That Understands India
When GPT-4 can write poetry and solve complex math problems, why does it struggle to answer basic questions about Indian agriculture or Ayurvedic principles? The answer is simple: most AI benchmarks test Western knowledge systems, leaving a massive blind spot for India-specific domains.
Today, we’re changing that with BhashaBench V1 – India’s first comprehensive, bilingual benchmark designed to evaluate how well AI models truly understand Indian knowledge systems.
Access LegalParam on Hugging Face: https://huggingface.co/bharatgenai/LegalParam
Why This Matters
Imagine a farmer in Punjab asking an AI assistant about pest management for their wheat crop, or a law student in Patna preparing for their civil services exam. Current AI models might give generic answers, but do they understand the nuances of Indian agriculture, the complexities of Indian law, or the depth of traditional Ayurvedic medicine?
India isn’t just another market for AI – it’s a unique ecosystem with:
- 93 million agricultural households who need advice on region-specific crops and practices.
- Millions of legal professionals and citizens navigating one of the world's most complex legal systems.
- A vibrant traditional medicine system that millions rely on for healthcare.
- A rapidly evolving financial landscape with unique regulatory frameworks.
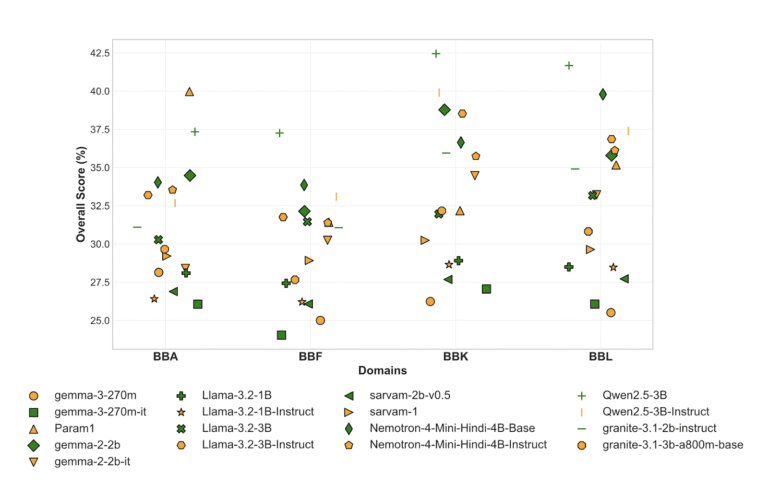
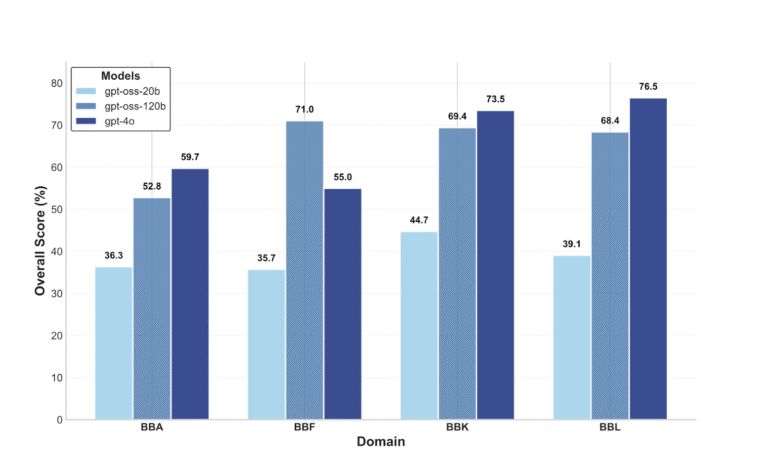
Yet when we tested 29 leading language models on Indian knowledge, the results were sobering. Even GPT-4o, one of the most advanced models, scored 76% on legal questions but dropped to just 59.74% on Ayurveda. Models consistently performed worse on Hindi content than English. Smaller models struggled even more.
The message was clear: AI models aren’t ready for India’s diverse knowledge landscape.
Introducing BhashaBench V1: Four Benchmarks, One Mission
BhashaBench V1 is not a single test – it’s a comprehensive suite of domain-specific benchmarks, each meticulously designed to evaluate AI on critical Indian knowledge systems.
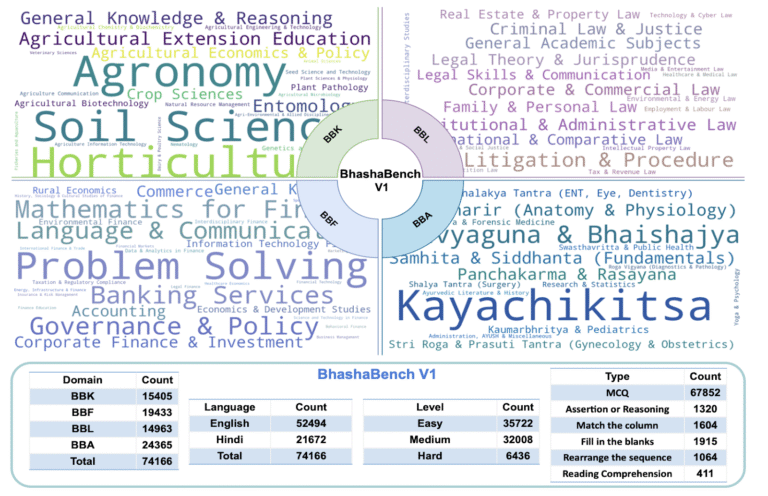
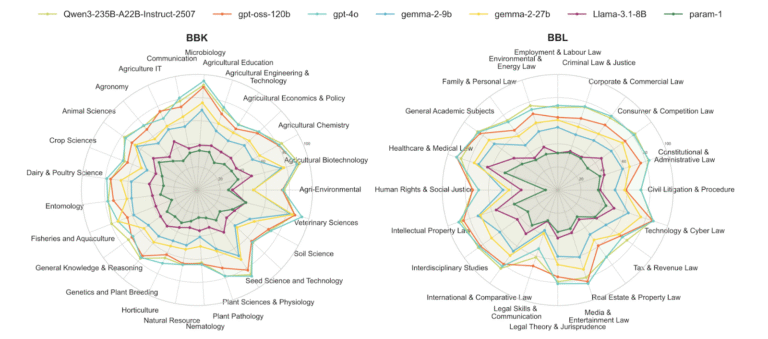
🌾 BhashaBench-Krishi (BBK): Agriculture
India’s first large-scale agricultural AI benchmark, built from 55+ government agricultural exams across the country.
What’s Inside:
- 15,405 questions spanning 25+ agricultural domains and 270+ topics.
- Coverage from soil science to agricultural policy, agronomy to horticulture.
- Questions in English (12,648) and Hindi (2,757).
- Real exam questions that assess practical, region-aware farming knowledge.
Effective legal reasoning requires synthesizing binding precedents, distinguishing cases, and understanding the evolving landscape of judicial interpretation across decades of Supreme Court and High Court decisions.
Why It Matters:
When a farmer asks about pest management for their Basmati crop or the best sowing time for cotton in Maharashtra, the model needs to understand India’s diverse agro-ecological zones, not just generic farming principles.
⚖️ BhashaBench-Legal (BBL): Indian Law
The first large-scale legal knowledge benchmark tailored for India’s jurisdictional contexts, based on 50+ official law exams.
What’s Inside:
- 24,365 questions spanning 20+ legal disciplines and 200+ topics.
- From constitutional law to cyber law, civil litigation to intellectual property.
- Questions in English (17,047) and Hindi (7,318).
- Covers practical, jurisdiction-specific legal knowledge.
Why It Matters:
Indian law is deeply contextual – understanding the IPC, CPC, Constitution, and state-specific regulations requires specialized knowledge that generic legal training doesn’t capture.
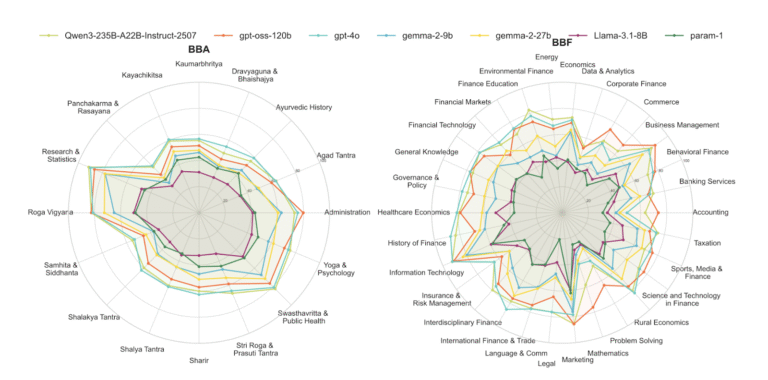
💼 BhashaBench-Finance (BBF): Financial Systems
India’s first comprehensive financial knowledge benchmark, drawing from 25+ government and institutional financial exams.
What’s Inside:
- 19,433 questions across 30+ financial domains.
- From banking services to taxation, corporate finance to rural economics.
- Questions in English (13,451) and Hindi (5,982).
- Covers India-specific regulations, policies, and financial practices.
Why It Matters:
India’s financial ecosystem is unique – from UPI transactions processing billions monthly to specific taxation frameworks. Models need to understand India’s regulatory landscape, not just global finance theory.
🌿 BhashaBench-Ayur (BBA): Traditional Medicine
The first comprehensive Ayurvedic knowledge benchmark, grounded in authentic texts and modern Ayurvedic education.
- 14,963 questions across 15+ Ayurvedic disciplines.
- From Kayachikitsa (internal medicine) to Panchakarma, Dravyaguna to diagnostics.
- Questions in English (9,348) and Hindi (5,615).
- Bridges classical texts with contemporary Ayurvedic practice.
Why It Matters:
Ayurveda is not alternative medicine in India – it’s a complete healthcare system with rigorous educational standards. Models need to understand traditional medicine with the same depth as modern medicine.
What Makes BhashaBench Different
📚 Authentic Sources
Every question comes from real government exams, professional certifications, and institutional assessments – the same tests that millions of Indians take for education and career advancement. These aren’t hypothetical scenarios; they’re validated by subject matter experts.
🎯 Granular Evaluation
With 90+ subdomains and 500+ topics across all benchmarks, we don’t just tell you a model scored 65% overall – we show you it excels at international finance but struggles with seed science, or performs well on constitutional law but fails at cyber law.
🗣️ Truly Bilingual
74,166 total questions split between English (52,494) and Hindi (21,672), reflecting how India actually communicates. This isn’t just translation – it’s about maintaining cultural authenticity across languages.
📊 Diverse Task Types
Multiple choice questions, assertion-reasoning, fill-in-the-blanks, match the column, reading comprehension, and more – testing different dimensions of understanding.
📈 Difficulty Stratification
Questions categorized into Easy, Medium, and Hard levels, allowing nuanced evaluation of where models succeed and where they hit their limits.
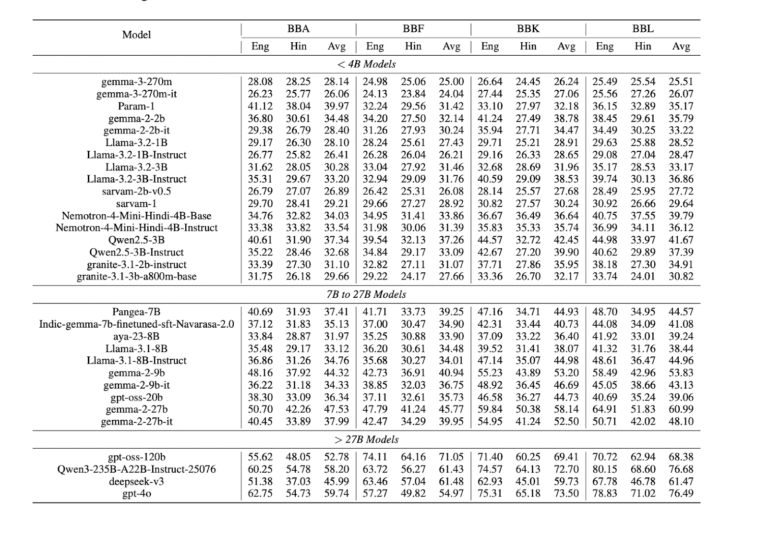
The Reality Check: What We Found
When we evaluated 29 language models across BhashaBench V1, the results revealed critical gaps:
Performance Varies Wildly Across Domains
Models that excel in one domain often struggle in others. Cyber Law and International Finance? Relatively strong. Panchakarma, Seed Science, and Human Rights? Significant weaknesses persist.
The Hindi Gap Is Real
Across every single domain, models performed better on English content than Hindi – even when testing identical knowledge. This reflects the persistent resource disparity between English and low-resource Indian languages.
Domain Expertise Matters More Than Model Size
While larger models generally performed better, the gaps narrowed in specialized contexts. A model’s breadth of training matters less than its depth in specific domains.
Even the Best Models Have Room to Grow
Top-performing models showed accuracy ranging from 34% to 76% across domains. There’s no “solved” benchmark here – BhashaBench presents meaningful challenges even for state-of-the-art models.
Real-World Impact
BhashaBench isn’t just academic evaluation – it’s about building AI that genuinely serves India’s needs:
- 🚜 Agriculture: Democratize access to expert crop advisory, pest management, and sustainable farming practices for farmers in remote areas who can't easily reach agricultural universities.
- ⚖️ Legal: Improve access to legal information and basic legal literacy in a country where justice remains inaccessible to millions due to complexity and cost.
- 💰 Finance: Enhance financial literacy and support India's digital payment ecosystem, helping millions navigate banking, taxation, and financial planning.
- 🌿 Healthcare: Preserve and disseminate traditional medical knowledge, supporting both Ayurvedic practitioners and patients seeking traditional treatments.
Built for the Community
BhashaBench is fully open-source under CC BY 4.0. We’re releasing:
- Complete datasets for all four benchmarks.
- Evaluation code using the lm-eval-harness framework.
- Model performance leaderboards.
- Documentation and resources.
Why open? Because solving India’s AI challenges requires the entire community – researchers, developers, organizations, and institutions working together.
What's Next
BhashaBench V1 is just the beginning. We’re actively working on:
- More languages: Expanding beyond English and Hindi to Tamil, Telugu, Bengali, and other Indian languages.
- More domains: Traditional crafts, regional governance, indigenous knowledge systems.
- More question types: Long-form reasoning, code generation, multimodal tasks.
Join the Movement
Whether you’re:
- Developing LLMs and need rigorous India-centric evaluation.
- Deploying AI solutions in Indian markets and want to benchmark performance.
- Researching multilingual AI with cultural authenticity.
- Building applications for agriculture, legal tech, fintech, or healthcare in India.
BhashaBench provides the evaluation framework you need.
🚀 Get Started:
- Access the datasets on Hugging Face.
- View the evaluation code on GitHub.
- Submit your model results to the leaderboard.
💬 Get Involved:
Have feedback? Want to contribute? Reach out to help expand BhashaBench to more languages and domains.
BhashaBench represents a collaborative effort to ensure AI development serves India’s billion-plus population with the cultural authenticity and domain expertise they deserve. It’s time our AI systems reflected India’s reality.
Overall Accuracy: 35.17%
Access the benchmark: bharatgenai/BhashaBench-Legal · Datasets at Hugging Face