India sovereign AI stack is taking shape with Sarvam AI, BharatGen Param 2 and vertical AI models unveiled at AI Impact Summit 2026, marking a new phase of indigenous AI innovation.
Reported by: Shraddha Goled (INC42)
SUMMARY
India’s sovereign AI push is taking shape through a layered stack spanning foundation models, public digital infrastructure and applied AI systems.
Efficiency-first architectures like Mixture of Experts are positioning Indian models as cost-effective alternatives in a compute-intensive global race.
Between 2023 and 2025, India climbed from seventh place to the top three globally in artificial intelligence competitiveness. And the last leg of this push coincided with India’s quest for sovereign AI.
According to Stanford University’s 2025 Global AI Vibrancy Tool, which ranks regions on AI talent, research depth, startup ecosystems and economic impact, India now sits just behind the United States and China — a rise that signals not just momentum, but structural capability.
It is against this backdrop that, as we look back at the India AI Impact Summit 2026 and what it held in store for the AI ecosystem, the main takeaway is that India’s sovereign AI players are ready for the next phase.
The likes of Sarvam AI, BharatGen Param 2, CoRover, Gnani.ai and others launched new products, expanded their platforms and showed off new hardware even – pointing to the future of AI in India. While these launches will be tested in the market against offerings from big AI giants and hyperscalers, there’s a momentum that’s hard to deny.
The launches signal the emergence of a layered Indian AI stack that spans foundation models, public digital infrastructure, and commercially deployable applied AI. For a country that has long excelled at building digital public rails, this moment marks an attempt to do the same for artificial intelligence.
The Foundation Layer: Large Models, Now Built in India
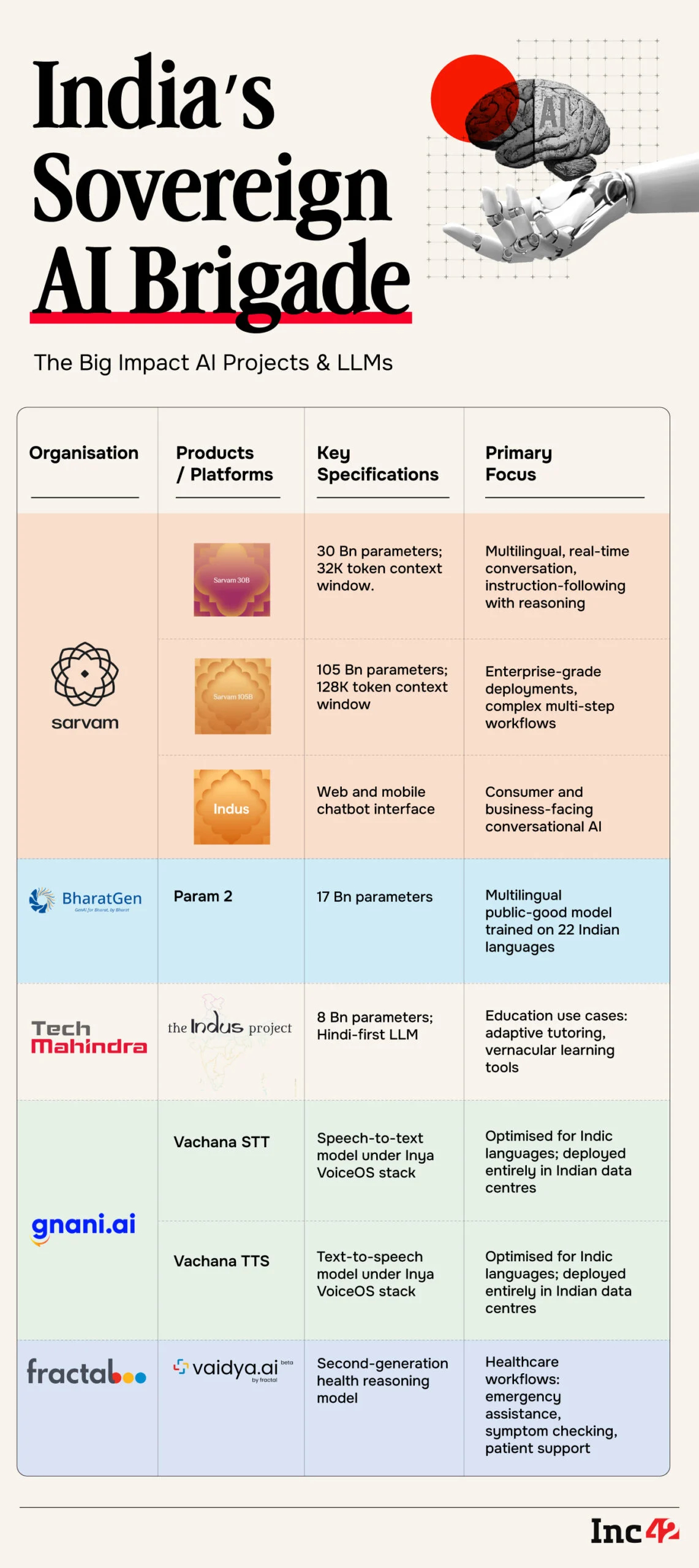
Bengaluru-based Sarvam AI, which has become one of the most prominent faces of India’s sovereign AI ambitions, unveiled two large language models: a 30-Bn parameter model and a 105-Bn parameter flagship.
The 30B model is designed as a multilingual, instruction-following system with reasoning capabilities and a 32,000-token context window suited for real-time conversational use cases. The 105B model, with a 128,000-token window, targets enterprise-grade deployments requiring complex, multi-step workflows and deeper contextual memory.
Both models were trained using compute resources provided under the government-backed IndiaAI Mission, positioning them squarely within the country’s strategic push to reduce reliance on foreign AI infrastructure.
Sarvam AI also introduced ‘Pravah’, described as a token factory aimed at industrial-scale AI usage. The idea is to lower inference costs and ‘manufacture’ tokens efficiently for enterprise and developer ecosystems. CEO Pratyush Kumar framed it as an effort to make AI “available to everybody at a fraction of the cost.”
The AI startup took it up a notch higher by introducing a chatbot based on these models. Called Indus, it is a chatbot for web and mobile users. With this, Sarvam AI entered a fast-growing market dominated by players like OpenAI and Anthropic. Indus serves as a chat interface for the 105B model and will have an emphasis on 22 Indian languages along with English.
However, Indus, in its present state, is a text-only model and cannot yet generate images, videos and does not have access to real-time information.
Meanwhile, BharatGen — a government-backed non-profit consortium — launched the second iteration of its Param model, called Param 2. At 17 Bn parameters, it is smaller than Sarvam’s offerings but positioned differently: as a multilingual public-good model trained extensively on Indian data across 22 languages.
According to BharatGen CEO Rishi Bal, Param 2 involved significant on-ground data collection, including digitising archival publications, sourcing recordings, and building structured datasets that reflect India’s linguistic diversity.
The goal, Bal said, is to deliver high-quality AI at low inference cost and make it widely accessible across governance, healthcare, education, agriculture, and enterprise use cases.
If Sarvam AI represents the private-sector push toward globally competitive foundation models, BharatGen reflects an attempt to create AI infrastructure in the spirit of India’s digital public goods ecosystem. The focus on token economics is notable. As model training costs balloon globally, the competitive battleground has increasingly shifted toward inference efficiency and affordability particularly in emerging markets.
Efficiency As A Strategy
In the beginning of 2025, a little known Chinese company emerged on the world stage, almost overnight, after its open source AI model proved that a lot could be done with limited resources and cost. DeepSeek’s R1 reasoning model, built at a reported cost of $6 Mn, as opposed to the $100 Mn used to build the then released GPT-4 by OpenAI. This caused intense scrutiny around massive infrastructural costs and resources being spent by the US counterparts.
It was around the time when US-based AI companies were falling over each other, building models each bigger than the previous using a high number of computing chips.
The R1 model popularised the mixture of experts (MoE) architecture. While the total parameter count is 671B, it only activates about 37B parameters per task, making it already more efficient than traditional architectures.
This is because in MoE architecture, multiple specialised sub-models (experts) are trained, and a separate gating mechanism decides which experts should handle each input. That means a model built on billions of parameters activates only a small part per token.
Notably, both Sarvam AI and BharatGen Param 2’s latest models are based on the MoE architecture. For instance, according to Param 2’s documentation on AI and machine learning platform HuggingFace, it activates only 2.4 Bn parameters per token for an inferencing task. Much like the team at DeepSeek that built the R1 model, both Sarvam AI and BharatGen relied on relatively small, tightly focused teams of specialists and engineers.
For their underlying model architecture, and the fact that they are localised and open source, the model offerings by Sarvam AI and BharatGen have ushered India to its own ‘Deepseek moment’ as many observers and ecosystem experts have noted.
But BharatGen’s Bal resists framing this as India’s “DeepSeek moment.”
Perhaps it’s something more uniquely ours, like India’s own turning point. It is certainly an extraordinary moment for India’s AI ecosystem. Multiple organisations are releasing promising models, and there is visible momentum building across the landscape. Just as importantly, Indian businesses are showing genuine interest in deploying Indian-built models,” Bal told Inc42.
“This may well be one of those inflection points we look back on years from now and say: that’s when something fundamentally shifted in the Indian AI ecosystem,” he added.
Beyond the initial excitement, the model providers are now set up for a bigger and more pertinent challenge, that of proving to be competitive against leading models from around the world. While BharatGen’s documentation and post-training workflows are available via its Hugging Face repository, Sarvam AI is yet to specify whether the training data or full training code would also be made public.
Verticalised Sovereign Models Come To The Fore
Beyond foundation models, the summit showcased applied AI systems targeting India-specific gaps. These are the so-called small language models or vertical models that have become the key focus of startups who are trying to distinguish themselves from LLM makers.
For instance, Tech Mahindra unveiled an 8B parameter Hindi-first large language model under Project Indus, focused on education use cases. Designed for digital classrooms, adaptive tutoring, and vernacular learning tools, the model aims to address the structural English bias embedded in many global AI systems.
Meanwhile, Gnani.ai introduced two speech models under its Inya VoiceOS stack: Vachana STT (speech-to-text) and Vachana TTS (text-to-speech). Both are optimised for Indic languages and, according to the company, built and deployed entirely within Indian data centres.
Fractal Analytics, which recently went public, launched the second generation of its health reasoning model called Vaidya 2.0. It claims to enhance healthcare workflows, enabling use cases such as emergency assistance, symptom checking, and end-to-end patient support.
It should be noted that Fractal Analytics has been chosen by the Ministry of Electronics and IT (MeitY) for its ₹10,000 Cr+ IndiaAI Mission to build a large reasoning model; Vaidya 2.0 represents one of the verticalised foundational models built towards this.
Alt: India’s Sovereign AI Brigade – The Big Impact Al Projects & LLMs (Photo credit: INC42)
The Real Test: Openness And Competitiveness
The excitement around sovereign AI now gives way to harder questions.
How open will these models be? BharatGen has made documentation and post-training workflows publicly available via Hugging Face repositories. Sarvam AI has not yet clarified whether full training datasets or code will be released.
How competitive are these systems against leading global models? Can they match benchmarks in reasoning, multilingual accuracy, and reliability? And perhaps most importantly whether they can sustain themselves economically in a market dominated by heavily capitalised global players.
Valuation gaps remain stark. While Indian AI startups operate at a fraction of the scale of giants like OpenAI, scale alone may not determine outcomes.
For perspective, Lightspeed Ventures and Khosla Ventures-backed Sarvam AI, with $50 Mn in its funding kitty, is valued at $200 Mn. It is eclipsed by the global giants such as OpenAI, which has reportedly reached a valuation of $500 Bn, one of the most valuable privately owned companies.
As AI pioneer Yann LeCun noted at the India AI Impact Summit 2026, India’s opportunity may not lie in catching up in the current race, but in leapfrogging investing in the next breakthrough rather than replicating the present one.
Whether this summit marks a symbolic milestone or a structural shift will depend on what happens next: enterprise adoption, developer ecosystem growth, and sustained investment in research. The inflection point, if it is one, has begun.
Article URL: INC42


