Contemporary large language models demonstrate significant limitations when applied to traditional medicine domains, particularly in understanding the complex philosophical frameworks and reasoning patterns inherent to Ayurvedic practice.
At BharatGen, we’re proud to introduce AyurParam – a 2.9B parameter transformer model built to bridge this gap.
Built upon the Param-1-2.9B-Instruct foundation, AyurParam has been specifically fine-tuned for Ayurvedic knowledge representation and represents the first large-scale attempt to encode traditional Indian medical knowledge into a neural language model capable of bilingual operation across English and Hindi, with comprehensive understanding of Sanskrit terminology and classical text interpretation.
Under the Hood: AyurParam’s Architecture
AyurParam inherits the core transformer architecture from Param-1-2.9B-Instruct with specialized adaptations for traditional medicine applications. The model employs a decoder-only configuration with grouped-query attention mechanisms optimized for long-context reasoning required in clinical Ayurvedic inference.
Technical Specifications:
- Parameters: 2.9 billion with domain-specific fine-tuning
- Architecture: Decoder-only transformer with 32 layers
- Attention: 16 heads per layer with 8 key-value heads for efficiency
- Context length: 2,048 tokens enabling complex multi-turn clinical reasoning
- Embeddings: Rotary positional embeddings (RoPE) with theta=10,000
- Activation: SiLU activation function throughout the network
- Precision: bf16-mixed for computational efficiency
- Vocabulary: 256,000 tokens plus 6 specialized tokens for structured inference
The model architecture prioritizes contextual understanding over parameter count, enabling sophisticated reasoning about traditional medicine concepts with computational efficiency suitable for practical deployment.
Data Preparation: Capturing 5,000 Years of Ayurvedic Wisdom
AyurParam’s training dataset draws from classical and contemporary Ayurvedic texts, carefully curated to reflect the full depth of Ayurvedic knowledge. The process combined thorough source selection, expert validation, and structured knowledge extraction.
Source Material:
- Books processed: ~1,000, including classical manuscripts and modern Ayurvedic literature
- Content volume: ~150,000 pages (~54.5 million words)
- Classical texts: 600 manuscripts from open-source archives
- Contemporary sources: 400 specialized texts from the internet covering Ayurvedic domains
Domain Coverage:
- Foundational texts: Charak Samhita, Sushrut Samhita, Ashtang Hruday
- Specialized branches: Kaaychikitsa, Panchakarma, Shalakya Tantra, Dravyaguna, Rasa Shastra, constitutional medicine, Balrog, Rog Nidan, Swasthvrutta
Data Processing Pipeline:
The dataset underwent a systematic process to ensure accuracy and coherence:
- Source Gathering: Texts preserved Sanskrit terminology with transliterations and contextual explanations.
- Q&A Generation: Page-level Q&A pairs focused on Ayurveda-related, context-grounded questions; domain experts reviewed all content.
- Taxonomic Organization: Knowledge structured according to core principles – Dosha, Dhatu, Mala, Srotas, Nidana, Chikitsa – reflecting authentic reasoning patterns.
- Final Dataset Construction: Three types of Q&A were created:
- General Q&A: Knowledge-based questions
- Thinking Q&A: Reasoning and application-oriented scenarios
- Objective Q&A: MCQs, fact-checking, structured assessments
The dataset is bilingual (English + Hindi) and includes both single-turn and multi-turn conversations, totaling ~4.8 million training samples. This preparation captures both explicit knowledge and subtle reasoning patterns, enabling AyurParam to address complex queries with practitioner-level insight.
Training Methodology and Optimization
AyurParam training employed supervised fine-tuning with specialized prompt templates designed for traditional medicine inference patterns. The training process balanced convergence efficiency with preservation of nuanced clinical reasoning capabilities.
Training Configuration:
- Base model: Param-1-2.9B-Instruct
- Framework: Hugging Face Transformers with TRL supervised fine-tuning
- Distributed training: Multi-node torchrun implementation
- Training samples: 4.8 million comprehensive examples
- Validation set: 800,000 held-out examples for convergence monitoring
- Training epochs: 3 with systematic convergence analysis
Optimization Parameters:
- Learning rate schedule: Linear decay with warmup initialization
- Base learning rate: 5e-6 with minimum decay to 0
- Batch configuration: Global batch size of 1,024 with micro-batching at 4
- Gradient accumulation: 32 steps for memory-efficient training
- Specialized tokens: Enhanced vocabulary with structured inference tokens
The training process incorporated custom prompt templates optimized for Ayurvedic consultation patterns, enabling the model to handle complex scenarios ranging from classical text interpretation to contemporary clinical applications.
How AyurParam Measures Up: Performance Highlights
Standard medical AI benchmarks lack the domain-specific complexity required to assess traditional medicine competency. AyurParam evaluation utilizes BhashaBench-Ayur (BBA), a comprehensive benchmark designed specifically for Ayurvedic knowledge assessment.
Benchmark Characteristics: BBA represents the most extensive traditional medicine evaluation framework available, incorporating questions from authentic government examinations and institutional assessments across India.
Assessment Scope:
- Question volume: 14,963 validated questions from 50+ official Ayurvedic examinations
- Source diversity: UPSC Medical Officer positions, State PSC AYUSH examinations, AIAPGET entrance assessments
- Domain coverage: 15+ specialized Ayurvedic disciplines from foundational principles to advanced clinical practice
- Language distribution: 9,348 English and 5,615 Hindi questions with Sanskrit terminology integration
- Difficulty stratification: Easy (7,944), Medium (6,314), and Hard (705) questions reflecting practitioner competency levels
Assessment Methodologies:
- Multiple choice questions for factual knowledge verification
- Fill-in-the-blank formats for terminological accuracy
- Match-the-column exercises for conceptual relationships
- Assertion-reasoning questions for clinical logic assessment
Domain-Specific Evaluation Criteria: BBA assesses competencies absent from generic medical benchmarks:
- Classical text interpretation across major Ayurvedic literature
- Dravyaguna mastery including herb identification and therapeutic properties
- Constitutional analysis and personalized treatment protocols
- Panchakarma procedure selection and contraindication awareness
- Integration of traditional principles with contemporary clinical safety standards
Performance Analysis
AyurParam demonstrates superior performance on BhashaBench-Ayur compared to both similar-sized and significantly larger general-purpose language models, validating the effectiveness of domain specialization for traditional medicine applications.
Overall Performance Metrics:
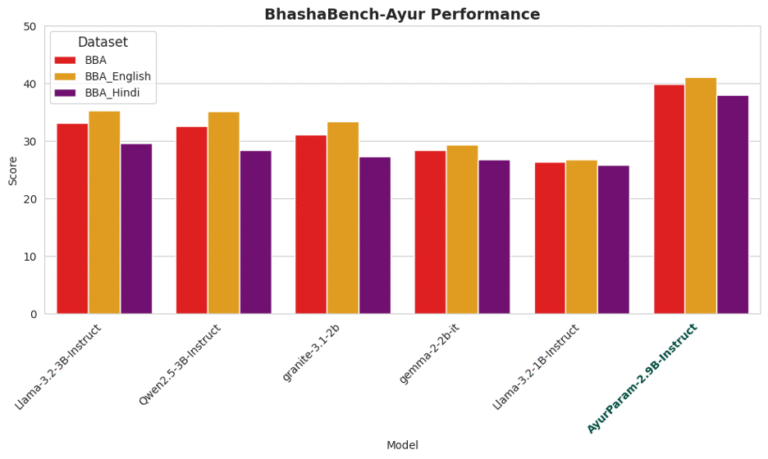
- Combined BBA accuracy: 39.97%
- English subset performance: 41.12%
- Hindi subset performance: 38.04%
- Cross-lingual consistency: 3.08% performance differential
Comparative Analysis: AyurParam significantly outperforms comparable models:
- Llama-3.2-3B-Instruct: 33.20% overall (6.77% improvement)
- Qwen2.5-3B-Instruct: 32.68% overall (7.29% improvement)
- granite-3.1-2b: 31.10% overall (8.87% improvement)
Efficiency Advantages: Despite substantially fewer parameters, AyurParam demonstrates competitive or superior performance against larger models:
- Gemma-2-27B-IT: 37.99% (2.0% improvement with 10x parameter efficiency)
- Llama-3.1-8B-Instruct: 34.76% (5.21% improvement with 3x parameter efficiency)
- Pangea-7B: 37.41% (2.56% improvement with 2.4x parameter efficiency)
Performance by Question Difficulty:
- Easy questions: 43.93% accuracy demonstrating strong foundational knowledge
- Medium questions: 35.95% accuracy showing clinical reasoning capability
- Hard questions: 31.21% accuracy indicating advanced competency retention
Question Type Performance:
- Multiple choice: 40.12% accuracy on primary assessment format
- Assertion-reasoning: 44.44% accuracy demonstrating logical inference capability
- Bilingual performance gap: Minimal 3.08% differential compared to 10-15% typical for general models
Why This Matters
Traditional medicine serves a significant portion of India’s population – it’s estimated that up to 80% of people in India use Ayurveda, either exclusively or alongside conventional Western medicine. Yet most medical LLMs remain optimized for Western biomedical frameworks and English-speaking users. AyurParam marks a fundamental shift – rooted in Bharat, designed for traditional knowledge, and built for real-world practitioners.
From AYUSH telemedicine and AI-enhanced Panchakarma centers to Ayurvedic education and rural wellness programs, AyurParam is our first step toward tradition-native LLMs that meet authentic needs.
This is about more than technological advancement – it’s about preserving and amplifying 5,000 years of healing wisdom through modern computational intelligence, ensuring that traditional knowledge systems remain relevant and accessible in an increasingly digital healthcare landscape.
Resources:
- Model Access: AyurParam on Hugging Face
- Benchmark Dataset: BhashaBench-Ayur
- Technical Documentation: Available in model repository
About BharatGen
BharatGen is a pioneering initiative by the BharatGen Consortium, envisioned as a comprehensive suite of Generative AI technologies designed to serve India’s diverse socio-cultural, linguistic, and industrial needs. Anchored under the Technology Innovation Hub (TIH), IIT Bombay, and supported by the National Mission on Interdisciplinary Cyber-Physical Systems (NM-ICPS), Department of Science and Technology (DST), Government of India, BharatGen is the nation’s first government-funded Multimodal Large Language Model (LLM) project. The initiative is developing inclusive and efficient AI across 22 Indian languages, integrating text, speech, and images to create robust AI solutions built for India’s realities.